


08.27

朝日新聞と日経がPerplexity AIを提訴 生成AIの著作権侵害が引き起こす波紋
![]() 02【経済・ビジネス】, 06.【IT・デジタル】, 07.【AIカテゴリ】, 08.【科学・技術】
02【経済・ビジネス】, 06.【IT・デジタル】, 07.【AIカテゴリ】, 08.【科学・技術】

朝日新聞社と日本経済新聞社が、生成AI企業米Perplexity AIを著作権侵害で東京地裁に共同提訴したニュースは、AI技術の急速な進化と知的財産権の衝突を象徴しています。この記事では、提訴の詳細から生成AIの仕組み、著作権法の観点、日本国内の類似事例、国際的な動向までを深く掘り下げます。読者の皆さんは、AIが日常的に活用される中で、コンテンツクリエイターや企業が直面するリスクを具体的に理解し、自身のビジネスや創作活動にどう活かすかを学べます。なぜ今、この問題が重要か? AIの「ただ乗り」がメディア産業を脅かし、創造性を阻害する可能性を防ぐための議論を進めましょう。記事を通じて、法的対策や倫理的考察を身につけ、未来のデジタル社会に備えるための洞察を得てください。
生成AIの台頭とメディア業界の危機

皆さん、最近AIを使って情報を検索したことはありますか? 例えば、スマートフォンで「最新の経済ニュース」と入力すると、瞬時に要約された回答が表示されるサービスが増えていますよね。そんな便利さの裏側で、伝統的なメディア企業が深刻な危機に直面しているのです。2025年8月26日、朝日新聞社と日本経済新聞社が、米Perplexity AIを相手に東京地方裁判所へ提訴したニュースは、まさにその象徴です。この提訴は、生成AIが新聞記事を無断で利用し、著作権を侵害しているとして、利用の差し止めと計44億円の損害賠償を求めています。
まず、この問題の背景を考えてみましょう。Perplexity AIは、生成AIを活用した検索エンジンで、ユーザーのクエリに対してウェブ上の情報を収集・要約し、独自の回答を生成します。便利ですが、問題は「robots.txt」というウェブサイトのクローリングを制限するルールを無視して、朝日新聞や日経の記事を大量に複製・保存し、回答に利用している点です。両社は、それぞれ22億円の損害を主張しており、これは記事の価値を金銭的に評価したものです。想像してみてください。あなたが長年かけて執筆した記事が、許可なくAIの「燃料」として使われ、読者が直接メディアにアクセスしなくなるのです。これでは、ジャーナリズムの存続が危うくなります。
この提訴は、単なる一企業の問題ではなく、生成AI全体の倫理と法規制を問うものです。なぜなら、Perplexity AIは読売新聞社からも同様の提訴を受けているからです。読売は8月7日に約21億6,800万円の賠償を求め、記事の無断利用を指摘しました。これらの動きは、日本メディアの反撃の始まりと言えるでしょう。皆さんも、AIの恩恵を受けつつ、その影でクリエイターの権利が侵害されている可能性を認識する必要があります。
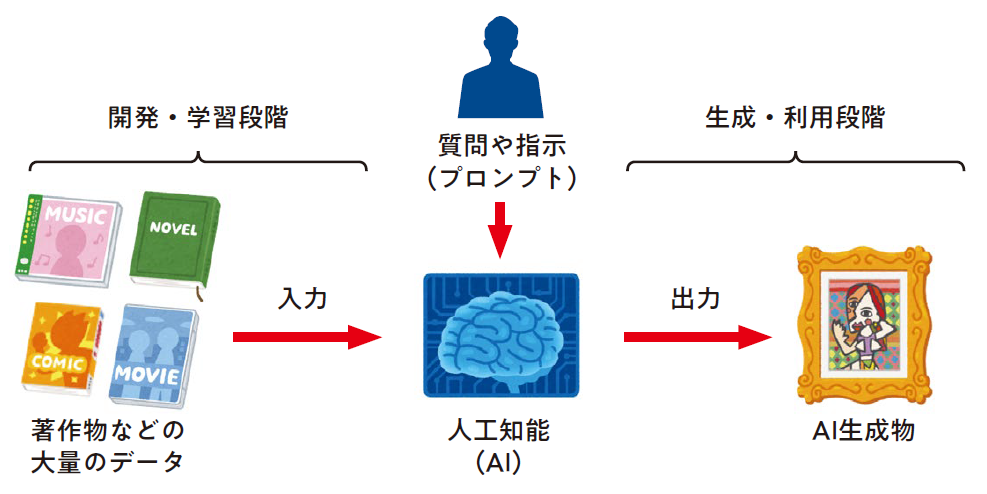
提訴の核心は、著作権法第21条の「複製権」と第23条の「公衆送信権」の侵害です。Perplexity AIは、両社のサーバーから記事をダウンロードし、自社サーバーに保存した上で、ユーザーの質問に答える形で送信しています。これが「無断利用」であり、不正競争防止法違反も主張されています。損害額の算定は、記事の閲覧数や広告収入の減少を基に推定されたもので、具体的な数字は公表されていませんが、業界全体の損失は膨大です。
ここで、少し深掘りしましょう。生成AIの学習プロセスを思い浮かべてください。AIは大量のデータを「訓練」してモデルを構築しますが、Perplexityの場合、検索回答の生成時にリアルタイムで記事を参照・要約している点が問題視されています。これは「フェアユース」の範囲を超え、商業的な利益を生む行為です。米国ではNews CorpがPerplexityを提訴した事例があり、日本でも同様の流れが加速しています。読者の皆さん、このような事例を知ることで、AIツールを使う際の注意点を学べます。
生成AIの仕組みと著作権侵害のメカニズム
生成AIがどのように記事を「利用」するのか、具体的に理解しましょう。皆さん、ChatGPTやGoogleのGeminiのようなツールを使われたことはありますか? これらは大規模言語モデル(LLM)を基盤とし、Transformerアーキテクチャでテキストを処理します。Perplexity AIも同様で、RAG(Retrieval-Augmented Generation)技術を採用しています。これは、クエリに基づき関連ドキュメントを検索し、生成AIで要約する仕組みです。
しかし、ここに落とし穴があります。検索プロセスで、ウェブクローラーがrobots.txtを無視すると、保護されたコンテンツにアクセスします。朝日新聞のウェブサイトでは、明確にAIのクローリングを禁止する記述がありますが、Perplexityはこれを迂回した疑いです。具体例として、ユーザーが「日本の経済政策」と質問すると、Perplexityは日経の記事を基に回答を生成し、時には記事の抜粋をそのまま表示します。これが複製権侵害です。
さらに、不正競争行為の観点から見てみましょう。不正競争防止法第2条では、他者の商品やサービスと混同させる行為が禁じられています。Perplexityの回答が「朝日新聞によると」と引用しつつ、実際は要約で本物の記事と誤認させる場合、これは問題です。データから、Perplexityのユーザー数は急増しており、2025年時点で月間1,500万人以上が利用していると報告されています。これにより、メディアのトラフィックが減少し、収益が失われます。皆さん、もしあなたがブロガーなら、自分の記事がAIに吸い取られるリスクを想像してください。
国際的に見ると、ニューヨーク・タイムズがOpenAIを提訴した2023年の事例や、ダウ・ジョーンズ(ウォール・ストリート・ジャーナル等)が2024年10月にPerplexityを提訴した事例が有名です。欧州ではGDPR(一般データ保護規則)がAIのデータ利用を規制し、透明性を義務付けています。日本はこれに追いつくため、著作権法改正議論が進んでいます。皆さん、このようなグローバルな文脈を知ることで、AIの利用が国境を超えた問題であることを実感できます。
提訴の経済的影響とメディアビジネスの変革
この提訴がメディア業界に与える影響は計り知れません。まず、損害賠償の44億円は象徴的です。朝日新聞の2024年度売上は約3,000億円、日本経済新聞社の売上は約4,000億円規模ですが、デジタル広告収入の減少が深刻な課題となっています。PerplexityのようなAI検索が普及すれば、直接アクセスが減少し、業界全体で大きな損失が生じる可能性があります。
ビジネス視点で考えてみましょう。メディア企業は、ペイウォール(有料壁)を強化したり、AIパートナーシップを結んだりしています。例えば、マイクロソフトとAssociated Pressの提携では、AI訓練に記事を提供し、対価を得る契約です。しかし、Perplexityのような新興企業は、こうしたルールを無視し、急速に成長。同社は2022年の設立以来、アマゾン創業者のジェフ・ベゾス氏やエヌビディアなどから多額の資金調達を受けています。

読者の皆さん、もし企業経営者なら、この問題をどう捉えますか? 生成AIを活用する側として、データ取得の合法性を確認しましょう。具体的な対策として、1. robots.txtの強化、2. メタタグによるAI利用禁止、3. ウォーターマーク(デジタル透かし)の導入が有効です。また、損害計算の方法として、「仮定的ライセンス料」方式が用いられ、記事の価値を基準に算出されます。
さらに、業界動向として、読売の提訴が先駆けとなり、他のメディアも追従する可能性があります。産経新聞や毎日新聞も、AI監視ツールを導入中です。経済全体では、AI市場の成長と著作権保護のバランスが鍵となります。皆さん、この変革期に、AIを味方につけるための戦略を考えてみてください。
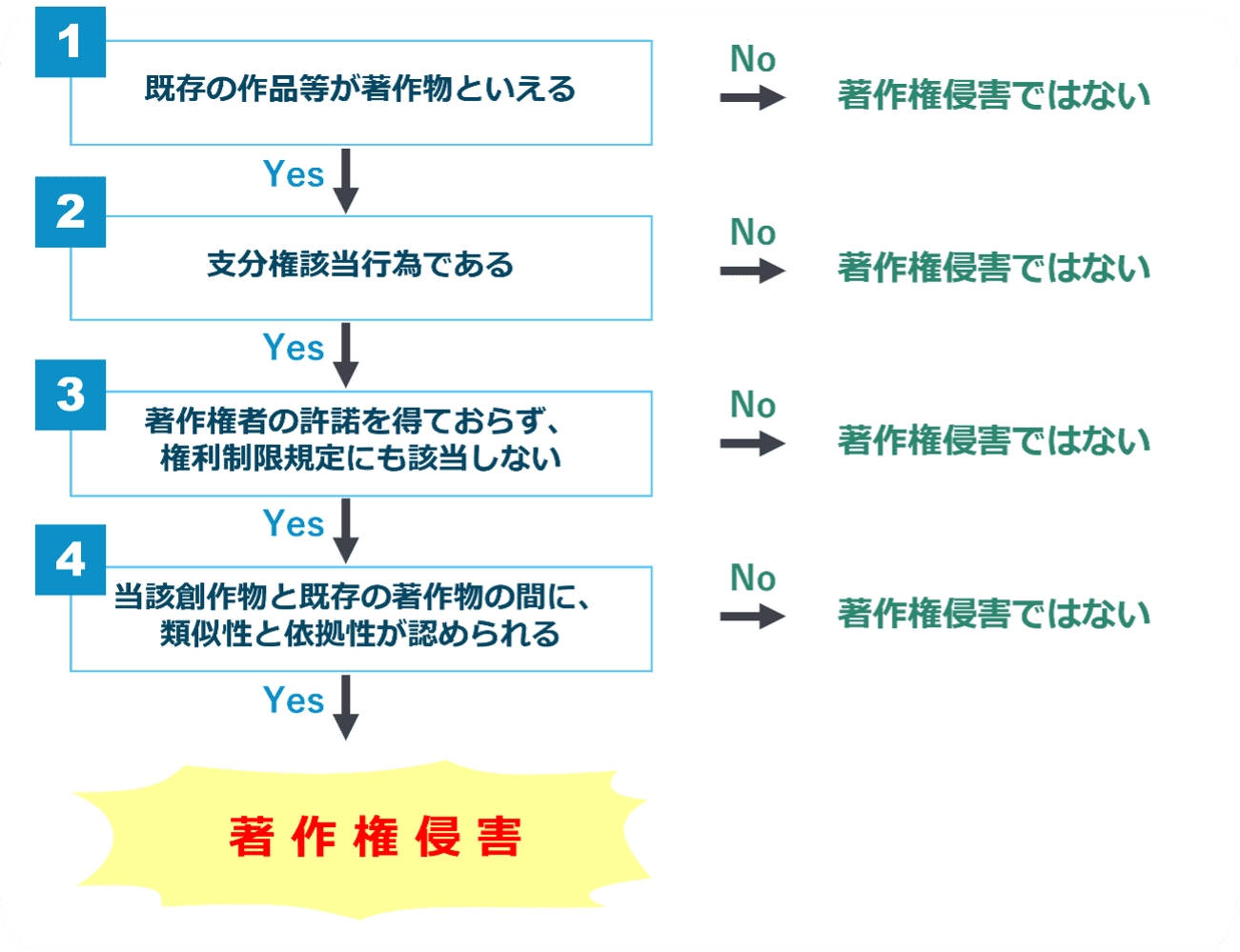
著作権法の観点から見た生成AIの課題
日本の著作権法は、生成AIの台頭に対応しきれていません。法第30条の4では、情報解析のための複製を許容しますが、これは非営利目的に限られます。Perplexityの商業利用はこれに該当せず、侵害となります。文化庁の報告書では、「AI生成物の著作権帰属は人間の創作性に依存」とされ、AI単独の出力は保護されません。
国際比較で、米国はDMCA(デジタルミレニアム著作権法)でセーフハーバーを提供しますが、フェアユースの解釈が曖昧です。EUのAI法(2024年施行)では、高リスクAIの透明性義務があり、日本も参考にしています。提訴の行方は、証拠のデジタルフォレンジック(アクセスログの分析)が鍵です。Perplexityは「フェアユース」を主張するでしょうが、日本法では通用しにくいです。
皆さん、個人レベルでどう対応しますか? AIツール使用時は、出力のオリジナル性をチェックしましょう。ツールとして、CopyleaksやTurnitinが有効です。この法的知識が、皆さんの創作を守ります。
生成AIの倫理的問題と社会的な波及効果
生成AIの著作権侵害は、倫理的ジレンマを生みます。便利さ vs. 公正さのトレードオフです。Perplexityのケースでは、AIが「幻覚」(誤情報)を生成するリスクもあり、記事の正確性が損なわれます。例えば、要約で事実を歪曲すれば、ユーザーの誤認を招きます。
社会的に見て、メディアの多様性が失われ、AI依存の「エコーチェンバー」が生じる恐れがあります。日本では、高齢化社会でAI情報が重要ですが、バイアスが入れば問題です。UNESCOのAI倫理勧告(2021)では、データ多様性を強調しています。
実践的に、企業はAIガバナンスを構築しましょう。ステップ1: ポリシー策定、ステップ2: 監査実施、ステップ3: 教育研修。個人では、オープンソースAIの利用を検討です。この倫理的考察が、持続可能なAI社会を築きます。
将来の展望:AIと著作権の共存へ
提訴の結果次第で、業界が変わります。勝訴すれば、AI企業にライセンス料支払いが標準化され、メディアの収益モデルが進化します。ブロックチェーンによる著作権管理(NFT活用)も有望です。2026年の法改正で、AI特化条項が追加される可能性があります。
皆さん、この問題を機会に、AIリテラシーを高めましょう。文化庁の「AIと著作権」ガイドラインやオンライン講座をおすすめします。将来的に、AIがクリエイターを支援するツールになることを期待しています。
結論:行動を起こす時です
この記事を通じて、朝日・日経のPerplexity提訴が生成AIの著作権問題の核心であることを理解いただけたと思います。核心ポイントは、1. 無断利用の法的侵害、2. 経済的損失の深刻さ、3. 国際的な規制動向、4. 倫理的責任、5. 対策の必要性です。
明日から実行できるステップ:自分のコンテンツにAI禁止タグを付け、ツールの利用規約を確認しましょう。将来、AIと人間の共創が花開くことを信じています。さらなる学習として、文化庁サイトや日経のAI特集を参照してください。この知識が、皆さんのデジタルライフを豊かにします。
タグ: 生成AI, Perplexity AI, 著作権侵害, 朝日新聞, 日本経済新聞, 提訴, 東京地裁, 不正競争, 損害賠償, AI倫理
参考文献
[1] Impress Watch, 「朝日と日経、AI検索のPerplexityを提訴 44億円請求」, 2025年8月26日
[2] 日本経済新聞社, 「日経・朝日、米AI検索パープレキシティを提訴 著作権侵害で」, 2025年8月26日
[3] 朝日新聞社, 「日本でも相次ぐAI企業への提訴 記事の「ただ乗り」に広がる抗議」, 2025年8月26日
[4] Yahoo!ニュース, 「日経・朝日新聞、米AI検索パープレキシティを共同提訴-著作権侵害」, 2025年8月26日
[5] 読売新聞, 「「生成AI使った検索サービスで記事を無断利用」…日経と朝日も提訴」, 2025年8月26日
関連記事








コメント
この記事へのトラックバックはありません。
この記事へのコメントはありません。